基于LSTM的二进制代码相似性检测
(编辑:jimmy 日期: 2026/5/4 浏览:2)
前言
近年来自然语言处理的快速发展,推出了一系列相关的算法和模型。比如用于处理序列化数据的RNN循环神经网络、LSTM长短期记忆网络、GRU门控循环单元网络等,以及用于计算词嵌入的word2vec、ELMo和BERT预训练模型等。近几年也出现了一些论文研究这些模型和算法在二进制代码相似性分析上的应用,可以实现跨平台的二进制代码相似性检测。本文根据上述模型和算法实现了一个基于word2vec和LSTM的简单模型用于判断两个函数或者两个指令序列是否相似。
总体框架

图1.PNG
函数嵌入
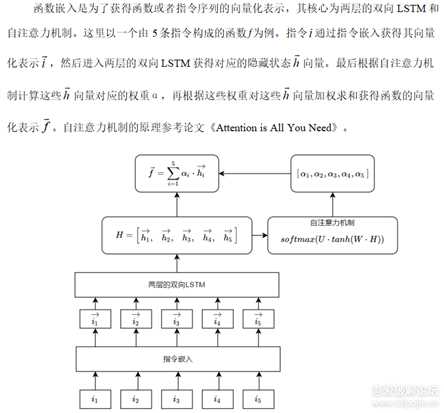
图2.PNG
LSTM是RNN的一个变体,由于RNN容易梯度消失无法处理长期依赖的问题。LSTM在RNN的基础上增加了门结构,分别是输入门、输出门和遗忘门,在一定程度上可以解决梯度消失的问题,学习长期依赖信息。LSTM的结构如下: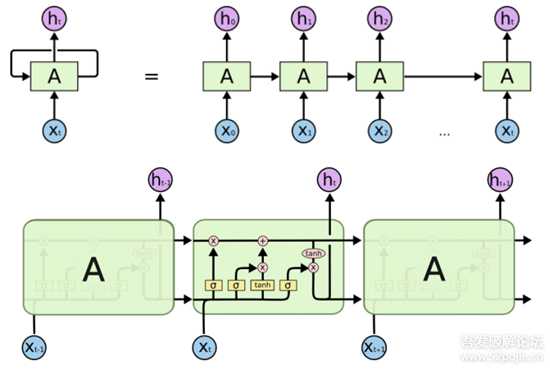
图3.PNG
运算规则如下: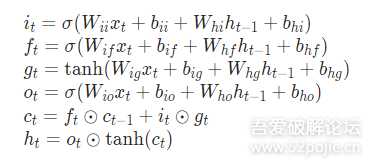
图4.png
W和b都是LSTM待学习的参数,具体参数细节可以参考pytorch的官方文档。
指令嵌入
指令嵌入的目的是也为了获得指令的向量化表示,方便LSTM等其它模型进行计算。这里使用word2vec的skip-gram模型实现。word2vec是谷歌公司开源的一个用于计算词嵌入的工具,包含cbow和skip-gram两个模型。指令嵌入具体实现细节如下:
(1)操作码、寄存器、加减乘符号以及中括号都看成一个词。比如mov dowrd ptr [0x123456+eax*4], ebx这条指令可以得到mov,dowrd,ptr,[,0x123456,+,eax,*,4,],ebx。然后这条指令看成一个句子送入word2vec进行训练,进而得到每一个词的向量化表示。
(2)为了减小词库的大小。操作数中超过0x5000的数值用mem,disp,imm代替
[0xXXXXXXXX] -> [mem][0xXXXXXXXX + index*scale + base] -> [disp + index*scale + base]0xXXXXXXXX -> imm(3)指令向量由一个操作码对应的向量和两个操作数对应的向量三部分组成,操作数不够的指令添加0向量补齐。对于超过两个操作数的指令,则最后两个操作数的向量求和取平均。操作数里面有多个词的情况下,各个词向量求和取平均表示当前操作数的向量。
代码实现
模型的代码实现用的是深度学习框架pytorch,word2vec的实现用的gensim库。word2vec的调用参数在insn2vec.py实现如下:
model = Word2Vec(tokensList, vector_size=wordDim, negative=15, window=5, min_count=1, workers=1, epochs=10, sg=1) model.save('insn2vec.model')tokensList的元素是一个列表,保存的是一条指令分词(tokenization)后的各个词序列。word2vec训练完成后保存到insn2vec.model文件,方便后续进行进一步的微调。
指令嵌入的实现在lstm.py文件中,实现如下:
class instruction2vec(nn.Module): def __init__(self, word2vec_model_path:str): super(instruction2vec, self).__init__() word2vec = Word2Vec.load(word2vec_model_path) self.embedding = nn.Embedding.from_pretrained(torch.from_numpy(word2vec.wv.vectors)) self.token_size = word2vec.wv.vector_size#维度大小 self.key_to_index = word2vec.wv.key_to_index.copy() #dict self.index_to_key = word2vec.wv.index_to_key.copy() #list del word2vec def keylist_to_tensor(self, keyList:list): indexList = [self.key_to_index[token] for token in keyList] return self.embedding(torch.LongTensor(indexList)) def InsnStr2Tensor(self, insnStr:str) -> torch.tensor: insnStr = RefineAsmCode(insnStr) tokenList = re.findall('\w+|[\+\-\*\:\[\]\,]', insnStr) opcode_tensor = self.keylist_to_tensor(tokenList[0:1])[0] op_zero_tensor = torch.zeros(self.token_size) insn_tensor = None if(1 == len(tokenList)): #没有操作数 insn_tensor = torch.cat((opcode_tensor, op_zero_tensor, op_zero_tensor), dim=0) else: op_token_list = tokenList[1:] if(op_token_list.count(',') == 0): #一个操作数 op1_tensor = self.keylist_to_tensor(op_token_list) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op_zero_tensor), dim=0)#tensor.mean求均值后变成一维 elif(op_token_list.count(',') == 1): #两个操作数 dot_index = op_token_list.index(',') op1_tensor = self.keylist_to_tensor(op_token_list[0:dot_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot_index+1:]) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor.mean(dim=0)), dim=0) elif(op_token_list.count(',') == 2): #三个操作数 dot1_index = op_token_list.index(',') dot2_index = op_token_list.index(',', dot1_index+1) op1_tensor = self.keylist_to_tensor(op_token_list[0:dot1_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot1_index+1:dot2_index]) op3_tensor = self.keylist_to_tensor(op_token_list[dot2_index+1:]) op2_tensor = (op2_tensor.mean(dim=0) + op3_tensor.mean(dim=0)) / 2 insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor), dim=0) if(None == insn_tensor): print("error: None == insn_tensor") raise insn_size = insn_tensor.shape[0] if(self.token_size * 3 != insn_size): print("error: (token_size)%d != %d(insn_size)" % (self.token_size, insn_size)) raise return insn_tensor #[len(tokenList), token_size] def forward(self, insnStrList:list) -> torch.tensor: insnTensorList = [self.InsnStr2Tensor(insnStr) for insnStr in insnStrList] return torch.stack(insnTensorList) #[insn_count, token_size]instruction2vec类的作用就是指令嵌入,token_size是词的维度大小,指令维度的大小为token_size*3。初始过程中主要是加载word2vec训练好的词向量word2vec.wv.vectors,方便InsnStr2Tensor把字符串形式的指令转换到向量。
函数嵌入的代码实现如下:
class SiameseNet(nn.Module): def __init__(self, hidden_size=60, n_layers=2, bidirectional = False): super(SiameseNet, self).__init__() self.insn_embedding = instruction2vec("./insn2vec.model") input_size = self.insn_embedding.token_size * 3 #input_size为指令的维度, hidden_size为整个指令序列的维度 self.lstm = nn.LSTM(input_size, hidden_size, n_layers, batch_first=True, bidirectional = bidirectional) self.D = int(bidirectional)+1 self.w_omega = nn.Parameter(torch.Tensor(hidden_size * self.D, hidden_size * self.D)) self.b_omega = nn.Parameter(torch.Tensor(hidden_size * self.D)) self.u_omega = nn.Parameter(torch.Tensor(hidden_size * self.D, 1)) nn.init.uniform_(self.w_omega, -0.1, 0.1) nn.init.uniform_(self.u_omega, -0.1, 0.1) def attention_score(self, x): #x:[batch_size, seq_len, hidden_size*D] u = torch.tanh(torch.matmul(x, self.w_omega)) #u:[batch_size, seq_len, hidden_size*D] att = torch.matmul(u, self.u_omega) #att:[batch_size, seq_len, 1] att_score = F.softmax(att, dim=1)#得到每一个step的hidden权重 #att_score:[batch_size, seq_len, 1] scored_x = x*att_score #类似矩阵倍乘 return torch.sum(scored_x, dim=1)#加权求和 def forward_once(self, input:list) -> torch.tensor: lengths = []#记录每个指令序列的长度 out = [] for insnStrList in input: insnVecTensor = self.insn_embedding(insnStrList)#把指令转换到向量 out.append(insnVecTensor) lengths.append(len(insnStrList)) pad_out = pad_sequence(out, batch_first=True)#填充0使所有handler的seq_len相同 pack_padded_out = pack_padded_sequence(pad_out, lengths, batch_first=True, enforce_sorted=False) packed_out,(hn,_) = self.lstm(pack_padded_out)#input shape:[batch_size, seq_len, input_size] #hn:[D*num_layers,batch_size,hidden_size] #out:[batch_size, seq_len, hidden_size*D],此时out有一些零填充 out,lengths = pad_packed_sequence(packed_out, batch_first=True) out = self.attention_score(out) return out def forward(self, input1, input2): out1 = self.forward_once(input1)#out1:[batch_size,hidden_size] out2 = self.forward_once(input2) out = F.cosine_similarity(out1, out2, dim=1) return out因为函数嵌入的输入是一对函数,所以该模型也是一个共享参数的孪生神经网络。hidden_size是函数的维度大小,这里设置成60维。attention_score对应的是注意力机制,w_omega是W矩阵,u_omega是U矩阵。pytorch的LSTM输入类型为[batch_size, seq_len, input_size]的张量,相当于是一个batch_sizeseq_leninput_size的矩阵,batch_size对应是函数个数,seq_len对应的是指令的个数。虽然LSTM可以处理任意长度的序列,但是为了加速运算,pytorch的lstm输入需要seq_len相同,所以需要添加0向量对齐。因为添加了0向量,对整个模型可能会有一定的影响。在经过W和H的点乘后,也就是torch.tanh(torch.matmul(x, self.w_omega))运算后需要一个特殊处理,需要把这些添加的0向量弄到负无穷大,这样在注意力机制的softmax运算中会使这部分向量对应的权重趋近于0,也就是注意力不应该放在这些0向量身上。这个处理我没有加,大家感兴趣的话自己改一改。
模型评估
指令的向量维度为30,函数的向量维度为60。数据集使用了6个二进制文件:
ntdll_7600_x64.dllntoskrnl_7600_x64.exewin32kfull_17134_x64.sysntdll_7600_x32.dllntoskrnl_7600_x32.exewin32kfull_17134_x32.sysx86和x64各三个文件,使用angr总共提取出4437个函数,函数名相同的x86和x64函数构成一个相似的正例。x86函数中随机选取一个不同名的x64函数构造一个负例,或者x64函数中随机选取一个不同名的x86函数构造一个负例。数据集样本的正负比例为1:1,总的样本数为4437*2,再按8:1:1划分为训练集、验证集和测试集。其实正负样本里应该还要加一些x86对应x86或者x64对应x64的正负样本,使数据分布的更均匀些。随机梯度下降法的学习率设置为0.09,批度大小8,迭代次数为50。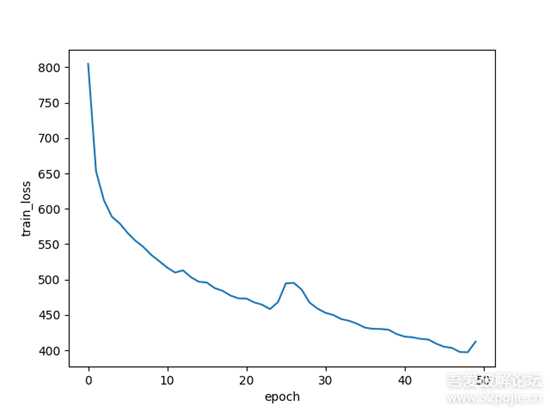
train_loss.png
val_loss.png
roc.png

result.PNG
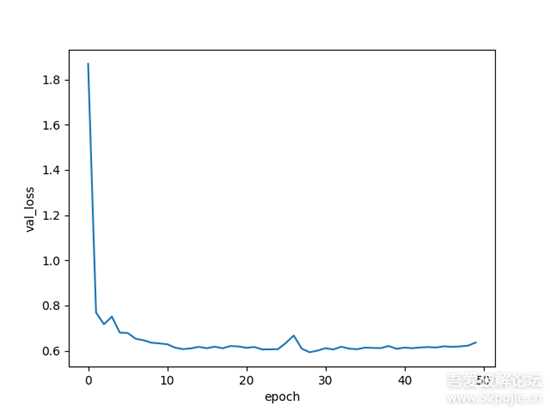
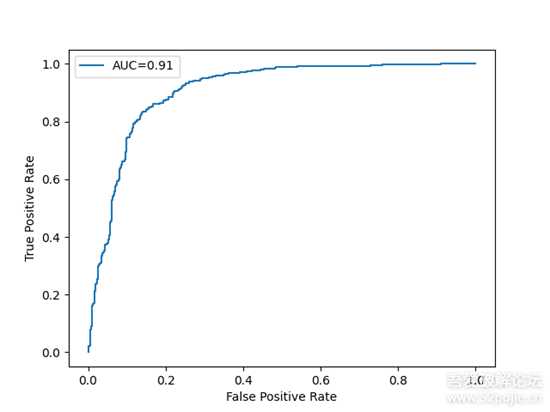
前面两张图片分别是训练集和验证集随着迭代次数的损失loss下降情况。可以看到根据训练集的loss还没收敛的情况下,验证集的loss就已经收敛不怎么下降。再训练下去的话,大概率是会过拟合(overfitting),主要原因还是数据太少了。第三张图是ROC曲线,该曲线的AUC(Area Under Curve)为0.91,AUC越接近1越好。根据ROC曲线可以得出当两个函数的余弦相似度的阈值设置0.24时,验证集和测试集的准确度都可以达到84%。
总结
模型准确度达不到90%以上的主要原因还是数据量不够,深度学习的核心在于足够多且有效的数据量。其次word2vec无法处理一词多义的问题,基于word2vec实现的指令嵌入,同样的指令计算出同样的向量化表示,即使有不同的上下文。比如有以下两个指令序列:
mov eax, [0x12345678] add eax, [0x12345678]shl eax, 2 shl eax, 2ret inc eax上述两条shl eax, 2指令有不同的上下文,应需要不同的向量化表示。最后,函数的处理应以基本块为单位,函数中的指令序列受控制流的影响不完全是顺序执行,控制流图的向量化表示可以引入一个图神经网络获取。
参考资料
SAFE: Self-Attentive Function Embeddings for Binary Similarity
A simple function embedding approach for binary similarity detection
Understanding LSTM Networks